

A couple of conversations with data leaders have reminded me of the data wrangling challenges that a number of you are still facing.
Despite the amount of media coverage for deep learning and other more advanced techniques, most data science teams are still struggling with more basic data problems.
Even well-established analytics teams can still lack the single customer view, easily accessible data lake or analytical playpen that they need for their work.
Insight leaders also regularly express frustration that they and their teams are still bogged down in data fire fighting’, rather than getting to analytical work that could be transformative.
Part of the problem may be lack of focus. Data and data management are often still considered the least sexy part of customer insight or data science. All too often, leaders lack clear data plans, models or strategy to develop the data ecosystem (including infrastructure) that will enable all other work by the team.
Back in 2015, we conducted a poll of leaders, asking about use of data models and metadata. Shockingly, none of those surveyed had conceptual data models in place, and half also lacked logical data models. Exacerbating this lack of a clear, technology-independent understanding of your data, all leaders surveyed cited a lack of effective metadata. Without these tools in place, data management is in danger of considerable rework and feeling like a DIY, best-endeavors frustration.
See also: Next Step: Merging Big Data and AI
So, what are the common data problems I hear, when meeting data leaders across the country? Here is one that crops up most often:
Too much time taken up on data prep
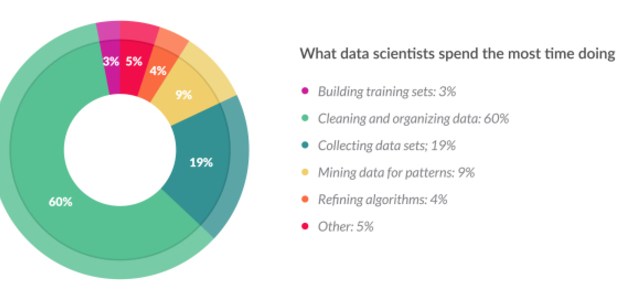
I was reminded of this often-cited challenge by a post on LinkedIn from Martin Squires, experienced leader of Boot’s insight team. Sharing a post originally published in Forbes magazine, Martin reflected how little has changed in 20 years. This survey shows that, just as Martin and I found 20 years ago, more than 60% of data scientists' time is taken up with cleaning and organizing data
 The problem might now have new names, like data wrangling or data munging, but the problem remains the same. From my own experience of leading teams, this problem will not be resolved by just waiting for the next generation of tools. Instead, insight leaders need to face the problem and resolve such a waste of highly skilled analyst time.
Here are some common reasons that the problem has proved intractable:
The problem might now have new names, like data wrangling or data munging, but the problem remains the same. From my own experience of leading teams, this problem will not be resolved by just waiting for the next generation of tools. Instead, insight leaders need to face the problem and resolve such a waste of highly skilled analyst time.
Here are some common reasons that the problem has proved intractable:
The problem might now have new names, like data wrangling or data munging, but the problem remains the same. From my own experience of leading teams, this problem will not be resolved by just waiting for the next generation of tools. Instead, insight leaders need to face the problem and resolve such a waste of highly skilled analyst time.
Here are some common reasons that the problem has proved intractable:
- Underinvestment in technology whose benefit is not seen outside of analytics teams (data lakes/ETL software)
- Lack of transparency to internal customers as to amount of time taken up in data prep (inadequate briefing process)
- Lack of consequences for IT or internal customers if situation is allowed to continue (share the pain)
- Analysis using data lake/playpen has shown potential
- Relatively easy to access data and not too many variables (in the quick win category for IT team)
- Important business problem that is widely seen as a current priority to fix (with rapid impact able to be measured)
- Good stakeholder relationship with business leader in application area (current or potential advocate)





