

For insurance companies, there’s a constant influx of data from almost everywhere: customers, marketing teams, sales representatives, underwriting departments, HR and more. These massive amounts of data can be used to make your company better, or so you’ve been told. But harnessing business value from this data isn’t as easy as it might seem. It takes more than collecting data and building models for AI to help a business.
In the last few years, a technology has emerged that can harness AI across all departments of a business like never before, enabling massive, company-wide returns. However, the technology alone isn’t enough; there must be the right combination of technology, people and process.
Feature Stores for Machine Learning
Data scientists love to dive deep into different algorithm alternatives, but the most effective way to get better predictive signals is to get the right data. For example, in media personalization, companies often used the fact that a particular user visited a particular site (like a luxury shoe brand) as an important data point. But this is deceptive. Recency also matters. If a visit to a particular site has been within, say, the last 48 hours, you get significantly better conversion on ads. You have to get the right data points represented to get a model to perform!
Data points that inform models are known as features. These are usually transformed data attributes, which together form the feature vectors that are the input to machine learning algorithms. The process of turning raw data into features is called feature engineering, and is — in my opinion — the critical success factor for practical ML projects that deal with corporate structured data.
Not only is feature engineering essential for model accuracy, it’s also incredibly time-intensive for data scientists. Data preparation takes 80% of data scientists' time, which means they only have 20% left to actually build, test and implement models. This makes it incredibly difficult and expensive to build models at the volume that would be necessary to provide value for every department of an insurance company.
Technology leaders like Uber, Google and Airbnb have spent years and millions of dollars designing infrastructure that makes it possible to unleash the power of AI throughout a company. The solution they have all converged on is a feature store.
A feature store is a central repository that stores features, data lineage and metadata associated with all the machine learning models in a company. In essence, it is a single source of truth for all of the data science work within one organization. Being able to share and re-use features boosts data science productivity by cutting down duplicate work and making it easy for data engineers, data scientists and ML engineers to collaborate. Each machine learning model becomes cheaper and easier to produce. (If you want to learn more about why that is, there’s a more in-depth resource here.)
See also: 6 Implications of Big Data for Insurance
Integrate Diverse Skill Sets in Data Science Teams
Even though feature stores are incredibly powerful tools, they are ultimately still tools, which means how they’re used will influence how helpful they are. Even with a feature store bridging the gaps inside a company, a “siloed” data science structure makes it hard to truly integrate AI into the enterprise.
Traditionally, the people who can manage large volumes of data and “do the math” of machine learning are sitting in their silos. They are away from the action — where the application interacts with customers, suppliers and employees. They are one step removed from the business.
But the AI or data science team is not equipped to get the job done independently. They simply do not have enough knowledge about the business or the applications that will deploy the models to lead to production applications that deliver business outcomes. The secret sauce to a successful AI implementation is diversity. Data scientists need to work side by side with people who know the business and the application from inception to completion.
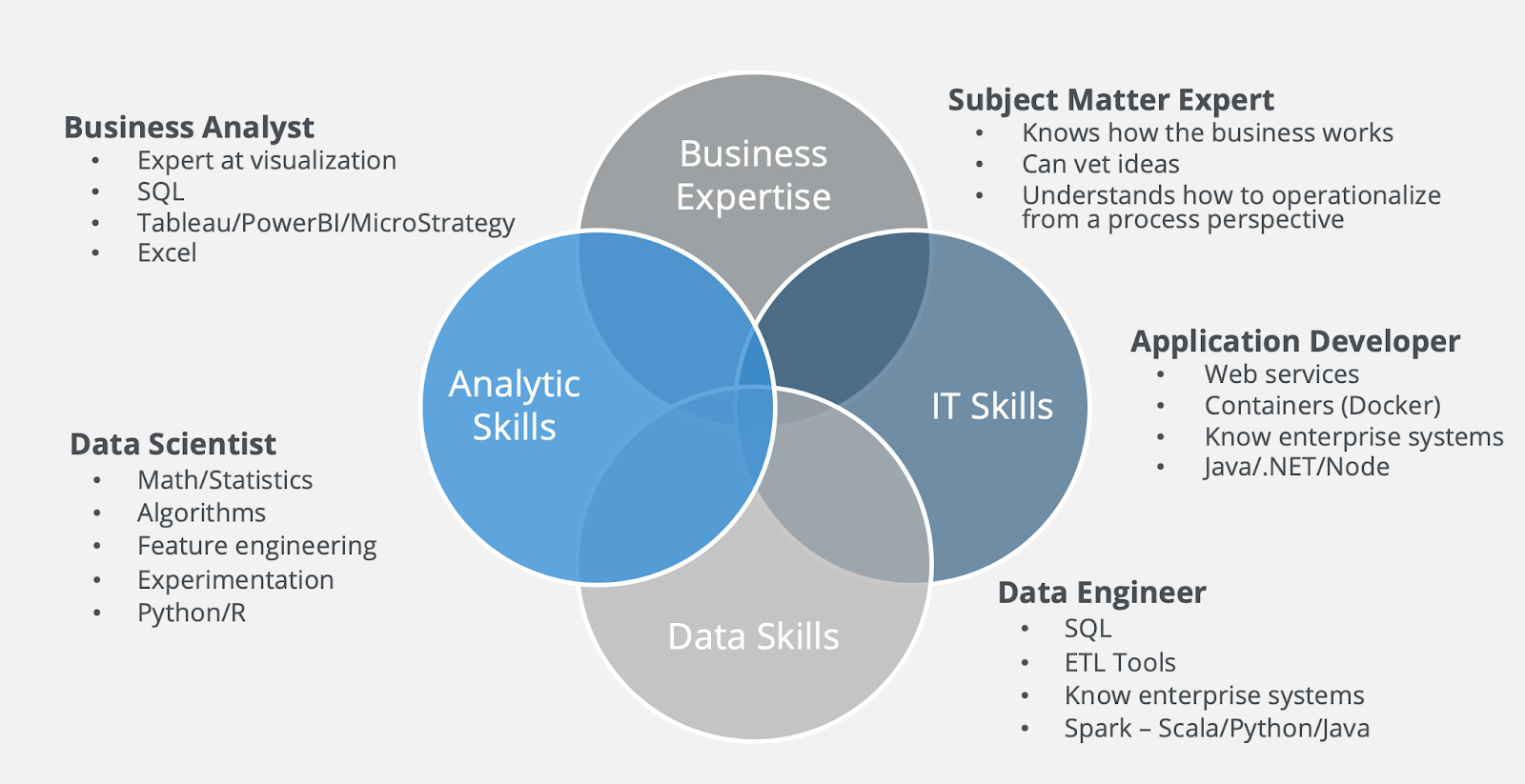
Culture of ML Experimentation
Machine learning projects need to include more than just subject matter experts and application developers as part of the data science and data engineering teams. To do ML well, you have to create a culture of experimentation within your data science team.
Markets change, bad actors innovate, the climate changes, the competitors change and so much more. What was the perfect feature vector on go-live might produce noise two months later, or worse — tomorrow. You must realize that an ML project will not thrive with a hands-off approach; it is a process of continuous experimentation and continuous improvement. So the secret is to keep the diverse team intact, frequently evaluating the deployed models, and able to experiment with new features.
See also: Insurance Outlook for 2021
Conclusion
The technologies and organizational silos of the past weren’t made to embed AI into the fabric of organizations, and as a result, companies that aren’t innovating aren’t benefiting from the full power of AI.
To inject AI throughout a company, the goal needs to be the continuous improvement of business outcomes.
You can achieve this by optimizing the two bottlenecks of the operational process:. First, overcome the feature bottleneck of the ML lifecycle with a feature store. Second, overcome the organizational bottleneck of the technology lifecycle by distributing data experts in every department of your company. Your teams will finally be able to demonstrate a significant ROI from your AI.



