Insurance is the business of assessing risks and pricing policies to match. As no two people are entirely alike, that means treating different people differently. But how to segment people without discriminating unfairly?
Thankfully, no insurer will ever use membership in a "protected class" (race, gender, religion...) as a pricing factor. It's illegal, unethical and unprofitable. But, while that sounds like the end of the matter, it’s not.
Take your garden-variety credit score. Credit scores are derived from
objective data that don’t include race and are highly predictive of
insurance losses. What’s not to like? Indeed, most regulators allow the use of credit-based insurance scores, and in the U.S. these can affect your premiums by up to
288%. But it turns out there is something not to like: Credit scores are also highly predictive of skin color, acting in effect as
a proxy for race. For this reason, California, Massachusetts and Maryland don’t allow insurance pricing based on credit scores.
Reasonable people may disagree on whether credit scores discriminate fairly or unfairly—and we can have that debate because we can all get our heads around the question at hand. Credit scores are a three-digit number, derived from a static formula that weighs
five self-explanatory factors.
But in the era of big data and artificial intelligence, all that could change. AI crushes humans at chess, for example, because it uses algorithms that no human could create, and none fully understand. The AI encodes its own fabulously intricate instructions, using billions of bits of data to train its machine learning engine. Every time it plays (and it plays millions of times a day), the machine learns, and the algorithm morphs.
What happens when those capabilities are harnessed for assessing risk and pricing insurance?
Many fear that such "black box" systems will make matters worse, producing the kind of proxies for race that credit scores do but without giving us the ability to scrutinize and regulate them. If five factors mimic race unwittingly, some say, imagine how much worse it will be in the era of big data!
But, while it's easy to be alarmist, machine learning and big data are more likely to solve the credit score problem than to compound it. You see, problems that arise while using five factors aren’t multiplied by millions of bits of data—the problems are divided by them.
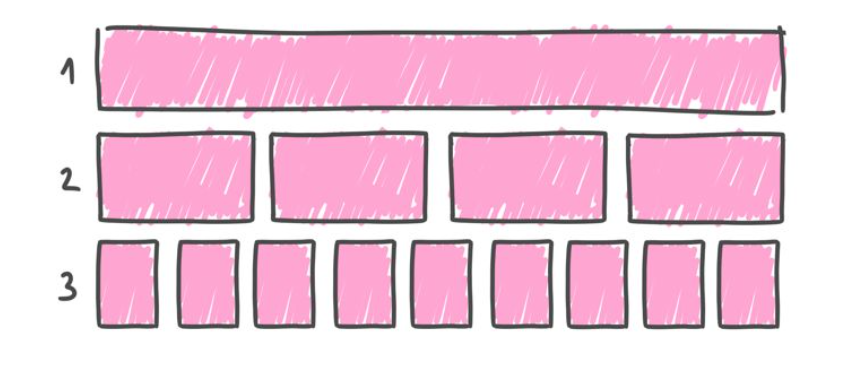
To understand why, let's think about the process of using data to segment—or "discriminate"—as evolving in three phases.
| Phase 1: |
 |
In Phase 1 all people are treated as though they are identical. Everyone represents the same risk and is therefore charged the same premium (per unit of coverage). This was commonplace in insurance until the 18th century.
Phase 1 avoids discriminating based on race, ethnicity, gender, religion or anything else for that matter, but that doesn't make it fair, practical or even legal.
One problem with Phase 1 is that people who are more thoughtful and careful are made to subsidize those who are more thoughtless and careless. Externalizing the costs of risky behavior doesn’t make for good policy, and isn't fair to those who are stuck with the bill.
Besides, people who are better-than-average risks will seek lower prices elsewhere - leaving the insurer with average premiums but riskier-than-average customers (a problem known as "adverse selection"). That doesn't work.
Finally, best intentions notwithstanding, Phase 1 fits the legal textbook definition of "unfair discrimination."
The law mandates that, subject to "practical limitations," a price is "unfairly discriminatory" if it "fails to reflect with reasonable accuracy the differences in expected losses." In other words, within the confines of what's practical, insurers must charge each person a rate that’s proportionate to the person's risk.
Which brings us to Phase 2.
| Phase 2: |
 |
Phase 2 sees the population divided into subgroups according to their risk profile. This process is data-driven and impartial, yet, as the data are relatively basic, the groupings are relatively crude. Phase 2—broadly speaking—reflects the state of the industry today, and it's far from ideal.
Sorting with limited data generates relatively few, large groups—and two big problems.
The first is that the groups may serve as proxies that affect protected classes. Take gender. Imagine, if you will, that women are—on average—better risks than men (say the average risk score for a woman is 40, on a 1-100 scale, and is 60 for men). We'd still expect many women to be sub-average risks, and many men to be better than average.
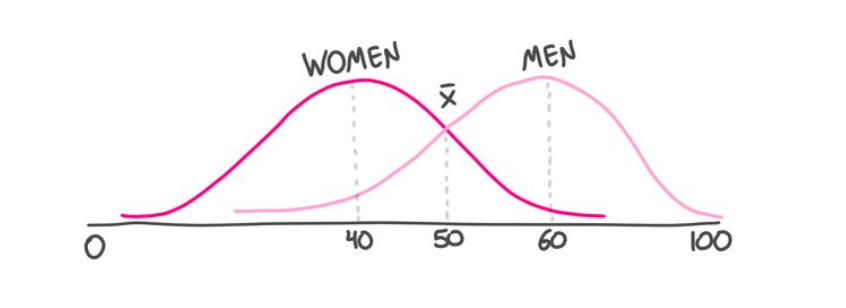
So while crude groupings may be statistically sound, Phase 2 might penalize low-risk men by tarring all men with the same brush.
The second problem is that—even if the groups don’t represent protected classes—responsible members of the group are still made to pay more (per unit of risk) than their less responsible compatriots. That’s what happens when you impose a uniform rate on a nonuniform group. As we saw, this is the textbook definition of unfair discrimination, which we tolerate as a necessary evil, born of practical limitations' But the practical limitations of yesteryear are crumbling, and there's a four-letter word for a "necessary evil" that is no longer necessary...
Which brings us to Phase 3.
| Phase 3: |
 |
Phase 3 continues where Phase 2 ends: breaking monolithic groups into subgroups. Phase 3 does this on a massive scale, using orders of magnitude more data, which machine learning crunches to produce very complex multivariate risk scores. The upshot is that today's coarse groupings are relentlessly shrunk, until—ultimately—each person is a group of one. A grouping that in Phase 2 might be a proxy for men, and scored as a 60, is now seen as a series of individuals, some with a risk score of 90, others of 30 and so forth. This series still averages a score of 60—but, while that average may be applied to all men in Phase 2, it's applied to none of them in Phase 3.
In Phase 3, large groups crumble under the weight of the data and the crushing power of the machine. Insurance remains the business of pooling premiums to pay claims, but now each person contributes to the pool in direct proportion to the risk the person represents—rather than the risk represented by a large group of somewhat similar people. By charging every person the same, per unit of risk, we sidestep the inequity, illegality and moral hazard of charging the careful to pay for the careless, and of grouping people in ways that serve as a proxy for race, gender or religion. It's like we said: Problems that arise while using five factors aren’t multiplied by millions of bits of data—the problems are divided by them.
 Insurance Can Tame AI
Insurance Can Tame AI
It's encouraging to know that Phase 3 has the potential to make insurance fairer, but how can we audit the algorithm to ensure it actually lives up to this promise? There's been some progress toward "explainability" in machine learning, but, without true transparency into that black box, how are we to assess the impartiality of its outputs?
By their outcomes.
But we must tread gingerly and check our intuitions at the door. It's tempting to say that an algorithm that charges women more than men, or black people more than white people, or Jews more than gentiles is discriminating unfairly. That's the obvious conclusion, the traditional one, and—in Phase 3—it's likely to be the wrong one.
Let's say that I am Jewish (I am) and that part of my tradition involves lighting a bunch of candles throughout the year (it does). In our home, we light candles every Friday night and every holiday eve, and we'll burn through about 200 candles over the eight nights of Hanukkah. It would not be surprising if I, and others like me, represented a higher risk of fire than the national average. So, if the AI charges Jews, on average, more than non-Jews for fire insurance, is that unfairly discriminatory?
It depends.
It would definitely be a problem if being Jewish, per se, resulted in higher premiums whether or not you’re the candle-lighting kind of Jew. Not all Jews are avid candle lighters, and an algorithm that treats all Jews like the "average Jew," would be despicable. That, though, is a Phase 2 problem.
A Phase 3 algorithm that identifies people’s proclivity for candle lighting, and charges them more for the risk that this penchant actually represents, is entirely fair. The fact that such a fondness for candles is unevenly distributed in the population, and more highly concentrated among Jews, means that, on average, Jews will pay more. It does not mean that people are charged more for being Jewish.
It's hard to overstate the importance of this distinction. All cows have four legs, but not all things with four legs are cows.
The upshot is that the mere fact that an algorithm charges Jews—or women, or black people—more on average does not render it unfairly discriminatory. Phase 3 doesn't do averages. In common with Dr. Martin Luther King, we dream of living in a world where we are judged by the content of our character. We want to be assessed as individuals, not by reference to our racial, gender or religious markers. If the AI is treating us all this way, as humans, then it is being fair. If I'm charged more for my candle-lighting habit, that's as it should be, even if the behavior I’m being charged for is disproportionately common among Jews. The AI is responding to my fondness for candles (which is a real risk factor), not to my tribal affiliation (which is not).
So if differential pricing isn't proof of unfair pricing, what is? What outcome is the telltale sign of unfair discrimination in Phase 3?
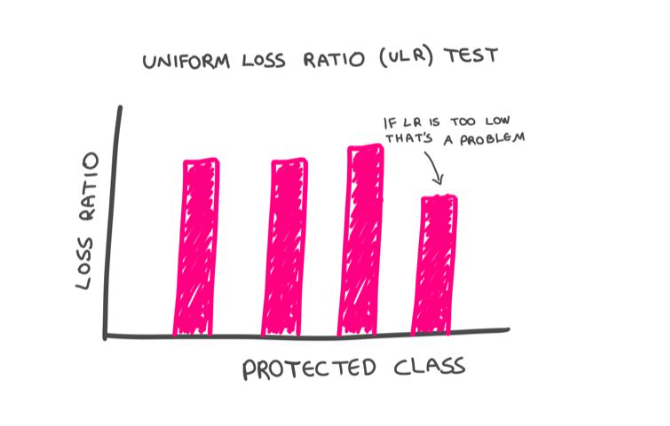
Differential loss ratios.
The "pure loss ratio" is the ratio of the dollars paid out in claims by the insurance company, to the dollars it collects in premiums. If an insurance company charges all customers a rate proportionate to the risk they pose, this ratio should be constant across their customer base. We'd expect to see fluctuations among individuals, sure, but once we aggregate people into sizable groupings—say by gender, ethnicity or religion—the law of large numbers should kick in, and we should see a consistent loss ratio across such cohorts. If that's the case, that would suggest that even if certain groups—on average—are paying more, these higher rates are fair, because they represent commensurately higher claim payouts. A system is fair—by law—if each of us is paying in direct proportion to the risk we represent.
This is what the proposed Uniform Loss Ratio (ULR) test, tests. It puts insurance in the enviable position of being able to keep AI honest with a simple, objective and easily administered test.
It is possible, of course, for an insurance company to charge a fair premium but then have a bias when it comes to paying claims. The beauty of the ULR test is that such a bias would be readily exposed. Simply put, if certain groups have a lower loss ratio than the population at large, that would signal that they are being treated unfairly. Their rates are too high, relative to the payout they are receiving.
ULR helps us overcome another major concern with AI. Even though machines do not have inherent biases, they can inherit biases. Imagine that the machine finds that people who are arrested are also more likely to be robbed. I have no idea whether this is the case, but it wouldn't be a shocking discovery. Prior run-ins with the police would, in this hypothetical, become a legitimate factor in assessing property-insurance premiums. So far, so objective.
The problem arises if some of the arresting officers are themselves biased, leading—for example—to an elevated rate of black people being arrested for no good reason. If that were the case, the rating algorithm would inherit the humans' racial bias: A person wouldn't pay more insurance premiums for being black, per se, but the person would pay more for being arrested—and the likelihood of that happening would be heightened for black people.
While my example is hypothetical, the problem is very real. Worried about AI-inherited biases, many people are understandably sounding the retreat. The better response, though, is to sound the advance.
You see, machines can overcome the biases that contaminate their training data if they can continuously calibrate their algorithms against unbiased data. In insurance, ULR provides such a true north. Applying the ULR test, the AI would quickly determine that having been arrested isn’t equally predictive of claims across the population. As data accumulate, the "been arrested" group would subdivide, because the AI would detect that for certain people being arrested is less predictive of future claims than it is for others. The algorithm would self-correct, adjusting the weighting of this datum to compensate for human bias.
(When a system is accused of bias, the go-to defense runs something like: "But we don't even collect information on gender, race, religion or sexual preference." Such indignation is doubly misplaced. For one, as we've seen, systems can be prejudiced without direct knowledge of these factors. For another, the best way for ULR-calibrated-systems to neutralize bias is to actually know these factors.)
Bottom line: Problems that arise while using five factors aren't multiplied by millions of bits of data—the problems are divided by them.
The Machines Are Coming. Look Busy.
Phase 3 doesn't exist yet, but it's a future we should embrace and prepare for. That requires insurance companies to redesign their customer journey to be entirely digital and reconstitute their systems and processes on an AI substrate. In many jurisdictions, how insurance pricing is regulated also must be rethought. Adopting the ULR test would be a big step forward. In Europe, the regulatory framework could become Phase-3-ready with minor tweaks. In the U.S., filing rates in a simple and static multiplication chart for human review doesn't scale as we move from Phase 2 to 3. At a minimum, regulators should allow these lookup-tables to include a column for a black box "risk factor." The ULR test would ensure these never cause more harm than good, while this additional pricing factor would enable emerging technologies to benefit insurers and insureds alike.
Nice to Meet You
When we meet someone for the first time, we tend to lump them with others with whom they share surface similarities. It's human nature, and it can be unfair. Once we learn more about that individual, superficial judgments should give way to a merits-based assessment. It's a welcome progression, and it's powered by intelligence and data.
What intelligence and data have done for humanity throughout our history, artificial intelligence and big data can start to do for the insurance industry. This is not only increasingly possible as a matter of technology, it is also desirable as a matter of policy. Furthermore, as the change will represent a huge competitive advantage, it is also largely inevitable. Those who fail to embrace the precision underwriting and pricing of Phase 3 will ultimately be adversely selected out of business.
Insurance is the business of assessing risks, and pricing policies to match. As no two people are entirely alike, that means treating different people differently. For the first time in history, we’re on the cusp of being able to do precisely that.