Current AI governance frameworks — SR 11-7, the NAIC Model AI Bulletin, the EU AI Act, and ISO 42001 — share a structural assumption: The task of governance is to verify whether an AI system performs as intended. They measure outputs. They assess model drift. They require explainability documentation and bias testing.
Few, if any, measure whether the trust that humans and institutions have placed in a given system is calibrated to its actual reliability in context. This is a different question — and in practice, a far more consequential one.
Ask any chief risk officer this: are your claims handlers trusting your AI system too much, not enough, or at the right level for the decisions being made? The honest answer, in almost every institution, is the same. We do not know. There is no instrument for this.
UnitedHealth acquired NaviHealth for over a billion dollars. Its nH Predict AI was embedded into Medicare Advantage care management. Internal managers allegedly set goals for clinical employees to keep patient rehabilitation stays within 1% of the algorithm's projections. According to plaintiffs in subsequent class action proceedings, the system carried a 90% error rate. It ran for years. Patients were denied rehabilitation care they needed. Congressional investigations followed. Class action proceedings continue in 2026.
The harm did not accumulate because the institution ignored the system. It accumulated because the institution trusted it completely — while nobody was measuring whether that trust was warranted.
The cases that caused the most harm — to the most people, for the longest time — were not the ones where systems failed visibly. They were the ones where institutions trusted systems that were quietly failing them.
Part I — The blind spot: two failure modes, one governance framework
There are two failure modes in AI governance. The first is visible failure: systems that perform poorly and people notice. Cigna's PxDx algorithm denied 300,000 claims in two months, spending 1.2 seconds per case, with physicians signing bulk rejections without opening patient files. ProPublica's 2023 investigation exposed the practice. Legitimacy collapsed within weeks of publication.
Lemonade's AI Jim publicly bragged that it analyses claimant videos for "non-verbal cues" to detect fraud, using up to 1,600 data points. AI researchers immediately identified the approach as methodologically unsound, with documented racial bias risk — one critic used the word "phrenology." The tweet was deleted within 48 hours. Class action suits for biometric data collection without consent followed. Visible failure — fast, noisy, and legibility-destroying.
The second failure mode is harder and more dangerous: systems that institutions trust completely while they quietly produce wrong outcomes. The cases below show where the documented evidence actually sits.
FIGURE 1 — SIX BANKING AND INSURANCE AI CASES: LEGITIMACY VS. OUTCOME QUALITY
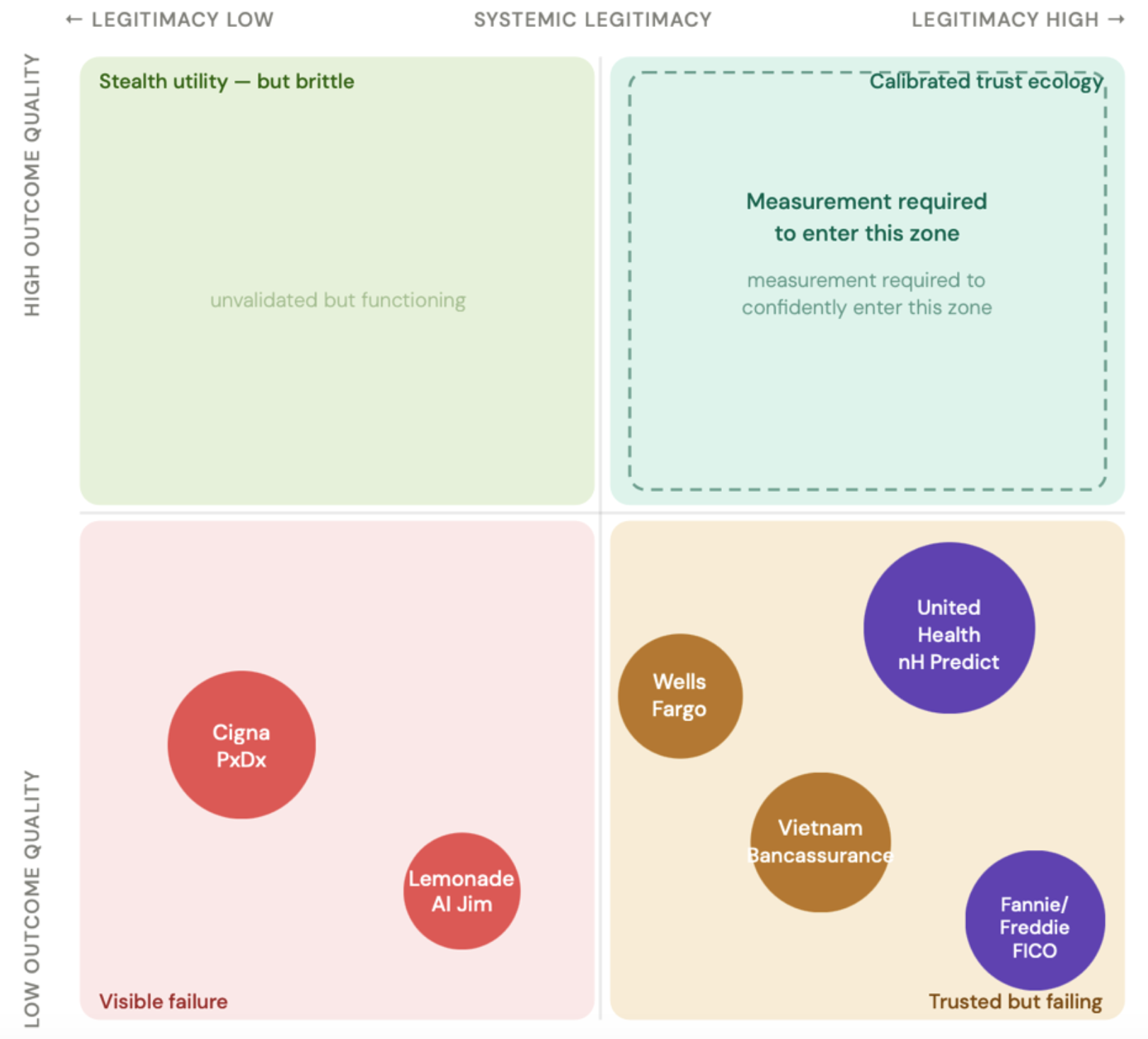

Bubble size reflects the relative scale of harm. The top half — good outcomes — is largely empty across documented cases. The dashed boundary signals that entry requires measured evidence, not aspiration. Top-left is labelled "Stealth utility — but brittle": AI producing useful outputs without validated trust. Common for routine decisions; fragile under regulatory scrutiny.
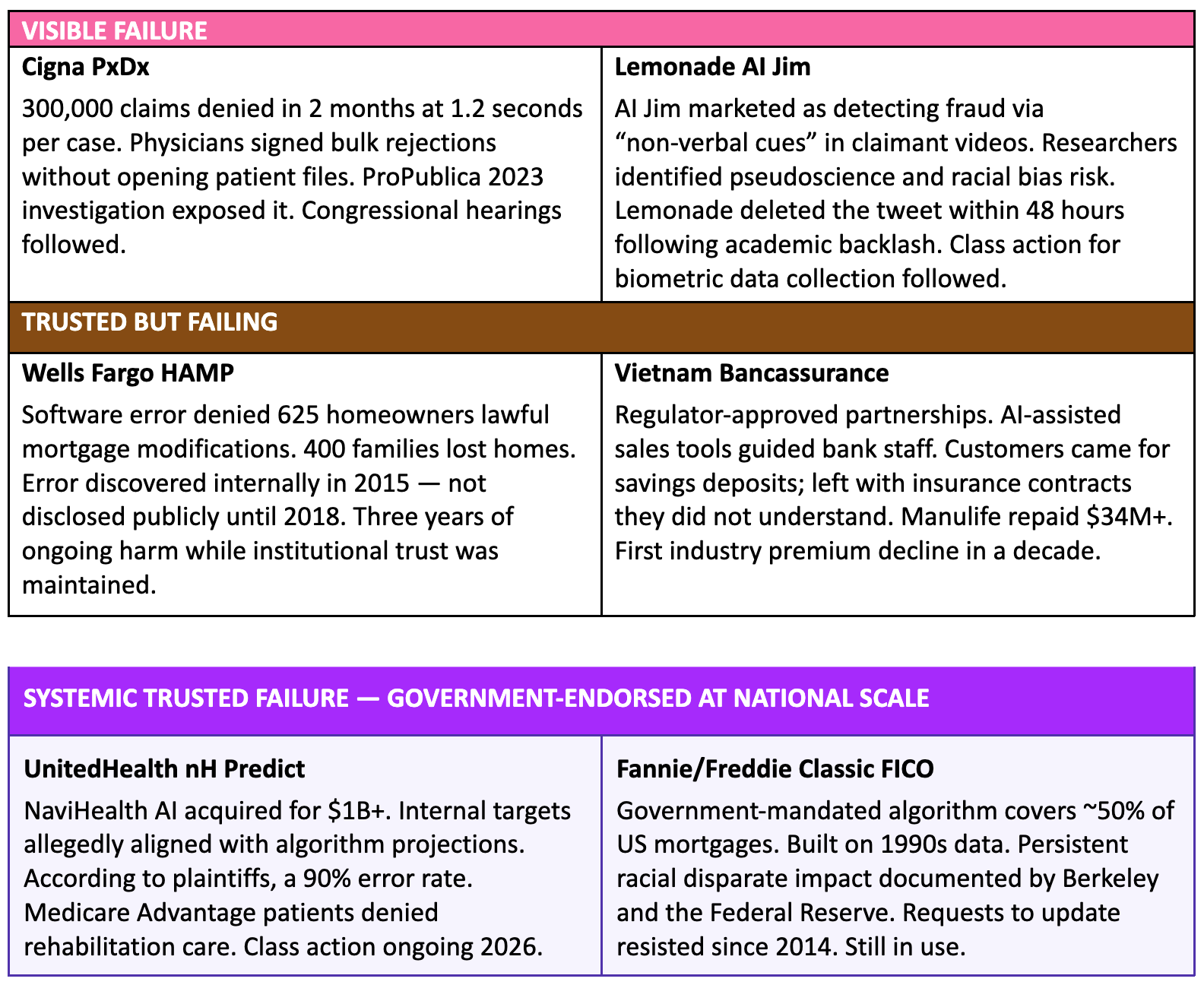
Wells Fargo's proprietary software denied 625 homeowners the mortgage modifications they were legally entitled to under HAMP (the Home Affordable Modification Program). Four hundred families lost their homes. Wells Fargo discovered the error in 2015 and did not disclose it publicly until 2018. For three years, institutional trust was maintained while the harm continued.
In Vietnam, regulators approved bancassurance partnerships between major insurers including Manulife and banks including SCB (Saigon Commercial Bank). Digital sales tools guided staff through recommendations. Customers came for savings deposits and left having signed long-term insurance contracts they did not understand. Manulife alone repaid more than $34 million. The industry's first premium decline in a decade followed.
Fannie Mae and Freddie Mac mandate use of the Classic FICO algorithm for conventional mortgage eligibility across approximately half of all U.S. mortgages. Built on 1990s data. Persistent racial disparate impact documented by Berkeley, the Federal Reserve, and investigative journalism. Requests to update the model have been resisted since at least 2014. The algorithm remains in use — government-backed and regulatory-endorsed.
The calibrated trust ecology quadrant remains largely empty. This is not because it is unachievable. It is because few organizations have yet been required to measure whether their trust is calibrated.
Part II — The Trust Ecology Framework: diagnosing what current governance misses
The Trust Ecology Framework (TEF) proposes that trust in AI-augmented decision systems has three interdependent dimensions. A failure in any one destabilizes the others.
FIGURE 2 — THE TRUST ECOLOGY FRAMEWORK: THREE DIMENSIONS (L, S, E)
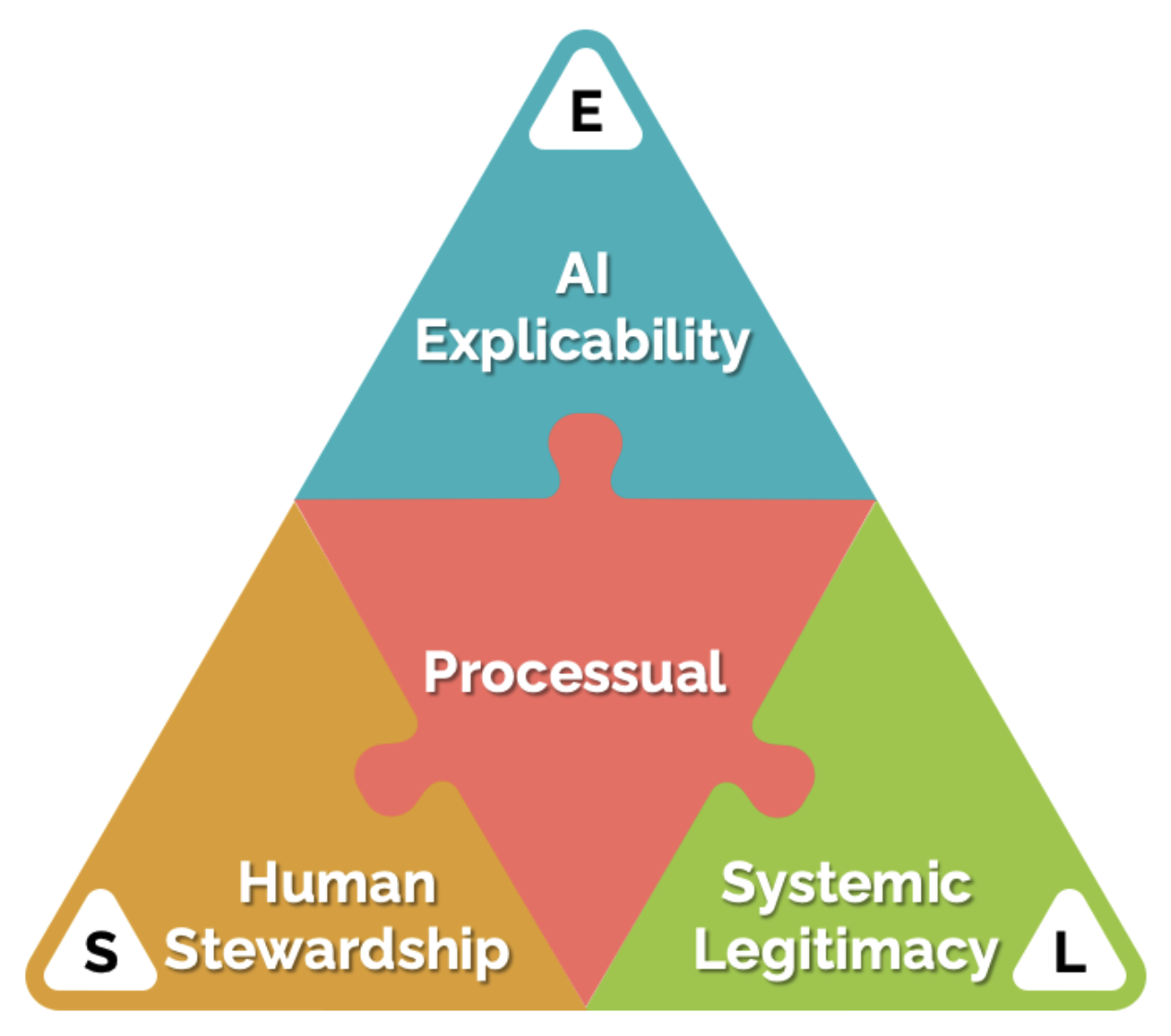
The processual center represents trust as a continuing equilibrium rather than a state achieved and held. Each case in Figure 1 failed on a specific dimension: UnitedHealth on Human Stewardship (S), Vietnam Bancassurance on Systemic Legitimacy (L), Fannie/Freddie FICO on AI Explicability (E).
Systemic Legitimacy (L) asks whether the institutional and regulatory environment supports trust that is appropriate rather than merely convenient. High legitimacy is not the same as warranted trust. UnitedHealth, Fannie/Freddie, and the Dutch Toeslagenaffaire all carried maximum institutional legitimacy alongside significant undetected harm.
Human Stewardship (S) asks whether the people operating the system are engaging with it at the right level of reliance. This is the governance question that audit programs and model validation cycles rarely ask. It operates at the level of the individual claims handler on a Tuesday afternoon, not the quarterly risk committee.
AI Explicability (E) asks whether the system can support the continuing scrutiny that legitimate trust requires — not just at validation, but continuously in operation. A system can pass all validation requirements and still be trusted at the wrong level if its outputs cannot be interrogated when they should be.
WHAT THIS MEANS FOR YOUR ORGANIZATION

Part III — The Triadic Trust Scale: what it measures and when
The Trust Ecology Framework operates at three levels. Being explicit about which level is currently available is itself a demonstration of rigor.

The Triadic Trust Scale (TTS) is a psychometric instrument that measures trust calibration across L, S, and E at the individual and institutional level. It distinguishes over-reliance from under-reliance, identifies which dimension is driving miscalibration, and produces a Trust Fidelity Index (TFI) score that creates a quantified baseline for monitoring over time. It does not replace model validation or bias testing — it measures the human-AI relationship that determines whether those validation results translate into appropriate operational behaviour.

Level 3 addresses a governance frontier that no current framework has mapped. As AI systems become agentic — routing claims without handler review, flagging fraud without adjuster involvement, pricing policies without underwriter sign-off — the question of trust calibration shifts from "are humans relying on this at the right level" to "should humans be in this loop at all, and how do we govern the ones who are not." That is a harder problem and an open research question. We frame it openly as an emerging research frontier.
Part IV — From diagnosis to action
If Systemic Legitimacy (L) is low, the institution has deployed AI where stakeholders do not perceive it as warranted. The intervention is transparency: explainability at the customer-facing level, accessible audit trails, accountability structures that are visible. Vietnam Bancassurance failed here — the regulatory framework endorsed the partnership model without ever validating whether customers could trust the decisions being made on their behalf.
If Human Stewardship (S) is low, staff are either deferring blindly or ignoring outputs that deserve weight. The intervention is stewardship design: decision protocols that structure when override is appropriate, override rate monitoring as a governance signal, training that builds interrogation capability rather than compliance behaviour. UnitedHealth failed here — the algorithm became a target to hit rather than a tool to question.
If AI Explicability (E) is low, the system cannot support the scrutiny that warranted trust requires. The intervention is technical: SHAP-level explainability for adverse decisions, model cards describing failure modes, continuous monitoring that detects distribution shift before it becomes miscalibration. Fannie/Freddie FICO fails here — the algorithm resists the scrutiny its scale of impact demands.
FIGURE 3 — FROM GOVERNANCE CHECKLIST TO TRUST AUDIT: WHAT TEF ADDS

TFI = Trust Fidelity Index, the composite score produced by the TTS. The incident response addition is the question that current post-mortems rarely ask — and the one that would have surfaced UnitedHealth, Wells Fargo, and Vietnam Bancassurance earlier.

The target quadrant is empty — and that is where the work begins
Calibrated trust ecology is not an aspiration. It is the absence of a known failure mode. Very few organizations have publicly demonstrated it, not because it is out of reach, but because the tools to measure it have not existed. The precedents for building those tools are in other high-stakes human-machine domains: aviation crew resource management, surgical checklists, nuclear control room protocols. In each case, the move from "the system is certified" to "the human-system relationship is calibrated" required a deliberate measurement program. Insurance and banking AI governance is at the same threshold.
The question is not whether your AI systems are performing. Your dashboards tell you that. The question is whether the trust your institution has placed in those systems is warranted — and whether the people using them are engaged at the right level to catch what the dashboards cannot show.
That question now has an instrument. The target quadrant is empty — and that is where the work begins.