Our survey of leading carriers shows that insurers are increasingly looking to integrate data scientists into their organizations. This is one of the most compelling and natural opportunities within the analytics function.
This document provides a summary of our observations on what insurers’ analytics function will look like in the future, the challenges carriers are currently facing to make this transition and how they can address them.
We base our observations on our experience serving a large portion of U.S. carriers. We supplemented our findings through conversations with executives at a representative sample of these carriers, including life, commercial P&C, health and specialty risk.
We also specifically address the issue of recruitment and retention of data scientists within the confines of the traditional insurance company structure.
The roles of actuaries and data scientists will be very different in 2030 than they are today
Actuaries have traditionally been responsible for defining risk classes and setting premiums. Recently, data scientists have started getting involved in building predictive analytics models for underwriting, in place of traditional intrusive procedures such as blood tests.
By 2030, automated underwriting will become the norm, and new sources of data may be incorporated into underwriting. Mortality prediction will become ever more accurate, leading to more granular (possibly at individual level) premium setting. Data scientists will likely be in charge of assessing mortality risks, while actuaries will be the ones setting premiums, or “putting a price tag on risk” – the very definition of what actuaries do.
Risk and capital management requires extensive knowledge of the insurance business and risks, and the ability to model the company’s products and balance sheet under various economic scenarios and policyholder assumptions. Actuaries’ deep understanding and skills in these areas will make them indispensable.
We do not expect this to change in the future, but by 2030, data scientists will likely play an increased role in setting assumptions underlying the risk and capital models. These assumptions will likely become more granular, based more on real-time data, and more plausible.
Actuaries have traditionally been responsible for performing experience studies and updating assumptions for in-force business. The data used for the experience studies are based on structured data in the admin system. Assumptions are typically set at a high level, varying by a few variables.
By 2030, we expect data scientists to play a leading role, and incorporate non-traditional data source such as call center or wearable devices to analyze and manage the business. Assumptions will be set at a more granular level – instead of a 2% overall lapse rate, new assumptions will identify which 2% of the policies are most likely to lapse.
See also: Wave of Change About to Hit Life Insurers
Actuaries are currently entirely responsible for development and certification of reserves per regulatory and accounting guidelines, and we expect signing off on reserves to remain the remit of actuaries.
Data scientists will likely have an increased role in certain aspects of the reserving process, such as assumptions setting. Some factor-based reserves such as IBNR may also increasingly be established based on data-driven and sophisticated techniques, which data scientists will likely play a role in.
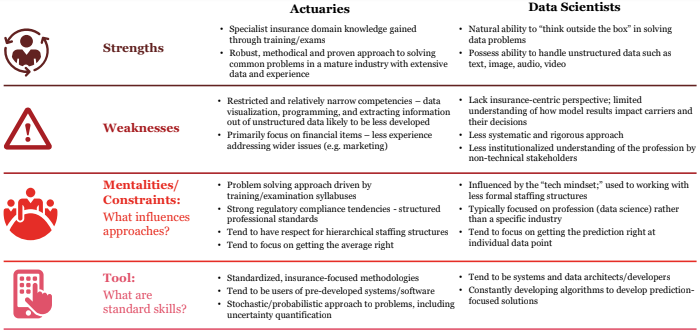
Comparing actuarial and data science skills
Although actuaries and data scientists share many skills, there are distinct differences between their competencies and working approaches.
 PwC sees three main ways to accelerate integration and improve combined value
1. Define and implement a combined operating model. Clearly defining where data scientists fit within your organizational structure and how they will interact with actuaries and other key functions will reduce friction with traditional roles, enhance change management and enable clearer delineation of duties. In our view, developing a combined analytics center of excellence is the most effective structure to maximize analytics’ value.
2. Develop a career path and hiring strategy for data scientists. The demand for advanced analytical capabilities currently far eclipses the supply of available data scientists. Having a clearly defined career path is the only way for carriers to attract and retain top data science (and actuarial) talent in an industry that is considered less cutting-edge than many others. Carriers should consider the potential structure of their future workforce, where to locate the analytics function to ensure adequate talent is locally available and how to establish remote working arrangements.
3. Encourage cross-training and cross-pollination of skills. As big data continues to drive change in the industry, actuaries and data scientists will need to step into each others’ shoes to keep pace with analytical demands. Enabling knowledge sharing will reduce dependency on certain key individuals and allow insurers to better pivot toward analytical needs. It is essential that senior leadership make appropriate training and knowledge-sharing resources available to the analytics function.
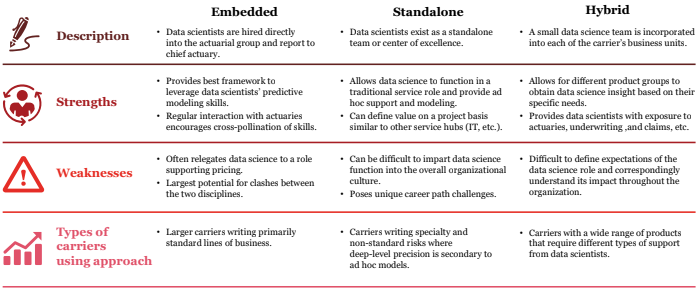
Options for integrating data scientists
Depending on the type of carrier, there are three main approaches for integrating data scientists into the operating model.
PwC sees three main ways to accelerate integration and improve combined value
1. Define and implement a combined operating model. Clearly defining where data scientists fit within your organizational structure and how they will interact with actuaries and other key functions will reduce friction with traditional roles, enhance change management and enable clearer delineation of duties. In our view, developing a combined analytics center of excellence is the most effective structure to maximize analytics’ value.
2. Develop a career path and hiring strategy for data scientists. The demand for advanced analytical capabilities currently far eclipses the supply of available data scientists. Having a clearly defined career path is the only way for carriers to attract and retain top data science (and actuarial) talent in an industry that is considered less cutting-edge than many others. Carriers should consider the potential structure of their future workforce, where to locate the analytics function to ensure adequate talent is locally available and how to establish remote working arrangements.
3. Encourage cross-training and cross-pollination of skills. As big data continues to drive change in the industry, actuaries and data scientists will need to step into each others’ shoes to keep pace with analytical demands. Enabling knowledge sharing will reduce dependency on certain key individuals and allow insurers to better pivot toward analytical needs. It is essential that senior leadership make appropriate training and knowledge-sharing resources available to the analytics function.
Options for integrating data scientists
Depending on the type of carrier, there are three main approaches for integrating data scientists into the operating model.
 Talent acquisition: Growing data science acumen
Data science talent acquisition strategies are top of mind at the carriers with whom we spoke.
Talent acquisition: Growing data science acumen
Data science talent acquisition strategies are top of mind at the carriers with whom we spoke.
 See also: Digital Playbooks for Insurers (Part 3)
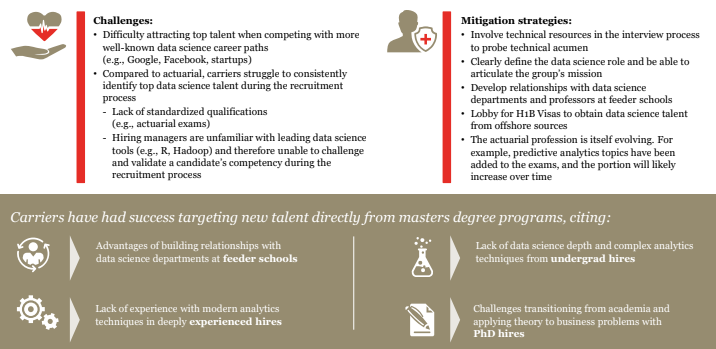
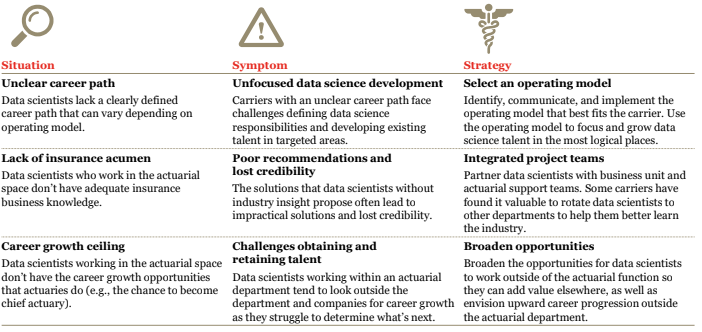
Data science career path challenges
The following can help carriers overcome common data science career path challenges.
See also: Digital Playbooks for Insurers (Part 3)
Data science career path challenges
The following can help carriers overcome common data science career path challenges.
 Case study: Integration of data science and actuarial skills
PwC integrated data science skills into actuarial in-force analytics for a leading life insurer so the company could gain significant analytical value and generate meaningful insights.
Issue
This insurer had a relatively new variable annuity line without much long-term experience gauging its risk. Uncertainty about excess withdrawals and rise in future surrender rates had major implications for the company’s reserve requirements and strategic product decisions. Traditional actuarial modeling approaches were limited to six to 12 months of confidence at a high level, with only a few variables. They were not adequate for major changes in the economy or policyholder behavior at a more granular level.
Solution
After engaging PwC’s support, in-force analytics expanded to use data science skills such as statistical and simulation modeling to explore possible outcomes across a wide range of economic, strategic and behavioral scenarios at the individual household-level.
Examples of data science solutions include:
Case study: Integration of data science and actuarial skills
PwC integrated data science skills into actuarial in-force analytics for a leading life insurer so the company could gain significant analytical value and generate meaningful insights.
Issue
This insurer had a relatively new variable annuity line without much long-term experience gauging its risk. Uncertainty about excess withdrawals and rise in future surrender rates had major implications for the company’s reserve requirements and strategic product decisions. Traditional actuarial modeling approaches were limited to six to 12 months of confidence at a high level, with only a few variables. They were not adequate for major changes in the economy or policyholder behavior at a more granular level.
Solution
After engaging PwC’s support, in-force analytics expanded to use data science skills such as statistical and simulation modeling to explore possible outcomes across a wide range of economic, strategic and behavioral scenarios at the individual household-level.
Examples of data science solutions include:
PwC sees three main ways to accelerate integration and improve combined value
1. Define and implement a combined operating model. Clearly defining where data scientists fit within your organizational structure and how they will interact with actuaries and other key functions will reduce friction with traditional roles, enhance change management and enable clearer delineation of duties. In our view, developing a combined analytics center of excellence is the most effective structure to maximize analytics’ value.
2. Develop a career path and hiring strategy for data scientists. The demand for advanced analytical capabilities currently far eclipses the supply of available data scientists. Having a clearly defined career path is the only way for carriers to attract and retain top data science (and actuarial) talent in an industry that is considered less cutting-edge than many others. Carriers should consider the potential structure of their future workforce, where to locate the analytics function to ensure adequate talent is locally available and how to establish remote working arrangements.
3. Encourage cross-training and cross-pollination of skills. As big data continues to drive change in the industry, actuaries and data scientists will need to step into each others’ shoes to keep pace with analytical demands. Enabling knowledge sharing will reduce dependency on certain key individuals and allow insurers to better pivot toward analytical needs. It is essential that senior leadership make appropriate training and knowledge-sharing resources available to the analytics function.
Options for integrating data scientists
Depending on the type of carrier, there are three main approaches for integrating data scientists into the operating model.
Talent acquisition: Growing data science acumen
Data science talent acquisition strategies are top of mind at the carriers with whom we spoke.
See also: Digital Playbooks for Insurers (Part 3)
Data science career path challenges
The following can help carriers overcome common data science career path challenges.
Case study: Integration of data science and actuarial skills
PwC integrated data science skills into actuarial in-force analytics for a leading life insurer so the company could gain significant analytical value and generate meaningful insights.
Issue
This insurer had a relatively new variable annuity line without much long-term experience gauging its risk. Uncertainty about excess withdrawals and rise in future surrender rates had major implications for the company’s reserve requirements and strategic product decisions. Traditional actuarial modeling approaches were limited to six to 12 months of confidence at a high level, with only a few variables. They were not adequate for major changes in the economy or policyholder behavior at a more granular level.
Solution
After engaging PwC’s support, in-force analytics expanded to use data science skills such as statistical and simulation modeling to explore possible outcomes across a wide range of economic, strategic and behavioral scenarios at the individual household-level.
Examples of data science solutions include:
- Applying various machine learning algorithms to 10 years of policyholder data to better identify most predictive variables.
- Using statistical matching techniques to enrich the client data with various external datasets and thereby create an accurate household-level view.
- Developing a simulation model to simulate policyholder behavior in a competitive environment as a sandbox to run scenario analysis over a 30-year period.