

Imagine you were suddenly refused insurance coverage, or your premium increased 50% just because of your skin color. Imagine you were charged more just because of your gender. It can happen, because of biased algorithms.
While technology improves our lives in so many ways, can we entirely rely on it for insurance policy?
Algorithmic Bias
Algorithms will most likely have flaws. Algorithms are made by humans, after all. And they learn only from the data we feed them. So, we have to struggle to avoid algorithmic bias -- an unfair outcome based on factors such as race, gender and religious views.
It is highly unethical (and even illegal) to make decisions based on these factors in real life. So why allow algorithms to do so?
Algorithmic Bias and Insurance Problems
In 2019, a bias problem surfaced in healthcare. An algorithm gave more attention and better treatment to white patients when there were black patients with the same illness. This is because the algorithm was using insurance data and predictions about which patients are more expensive to treat. If algorithms use biased data, we can expect the results to be biased.
It doesn't mean we need to stop using AI -- but, rather, that we must make an effort to improve it.
How Does Algorithmic Bias Affect People?
Millions of people of color were already affected by algorithmic bias. This bias mostly occurred in algorithms used by healthcare facilities. Algorithmic bias has also influenced social media.
It is essential to keep working on this problem. In the U.S. alone, algorithms manage care for about 200 million people. It is difficult to work on this issue because health data is private and thus hard to access. But it's simply unacceptable that Black people had to be sicker than white people to get more serious help and would be charged more for the same treatment.
How to Stop This AI Bias?
We have to find factors beyond insurance costs to use in calculating someone's medical fees. It's also imperative to continually test the model and to offer those affected a way of providing feedback. By acknowledging feedback every once in a while, we ensure that the model is working as it should.
See also: How to Evaluate AI Solutions
We have to use data that reflects a broader population and not just one group of people -- if there is more data collected on white people, other races may be discriminated against.
One approach is "synthetic data," which is artificially generated and which a lot of data scientists believe is far less biased. There are three main types: data that has been fully generated, data that has partially been generated and data that was corrected from real data. Using synthetic data makes it much easier to analyze the given problem and come to a solution.
Here is a comparison:
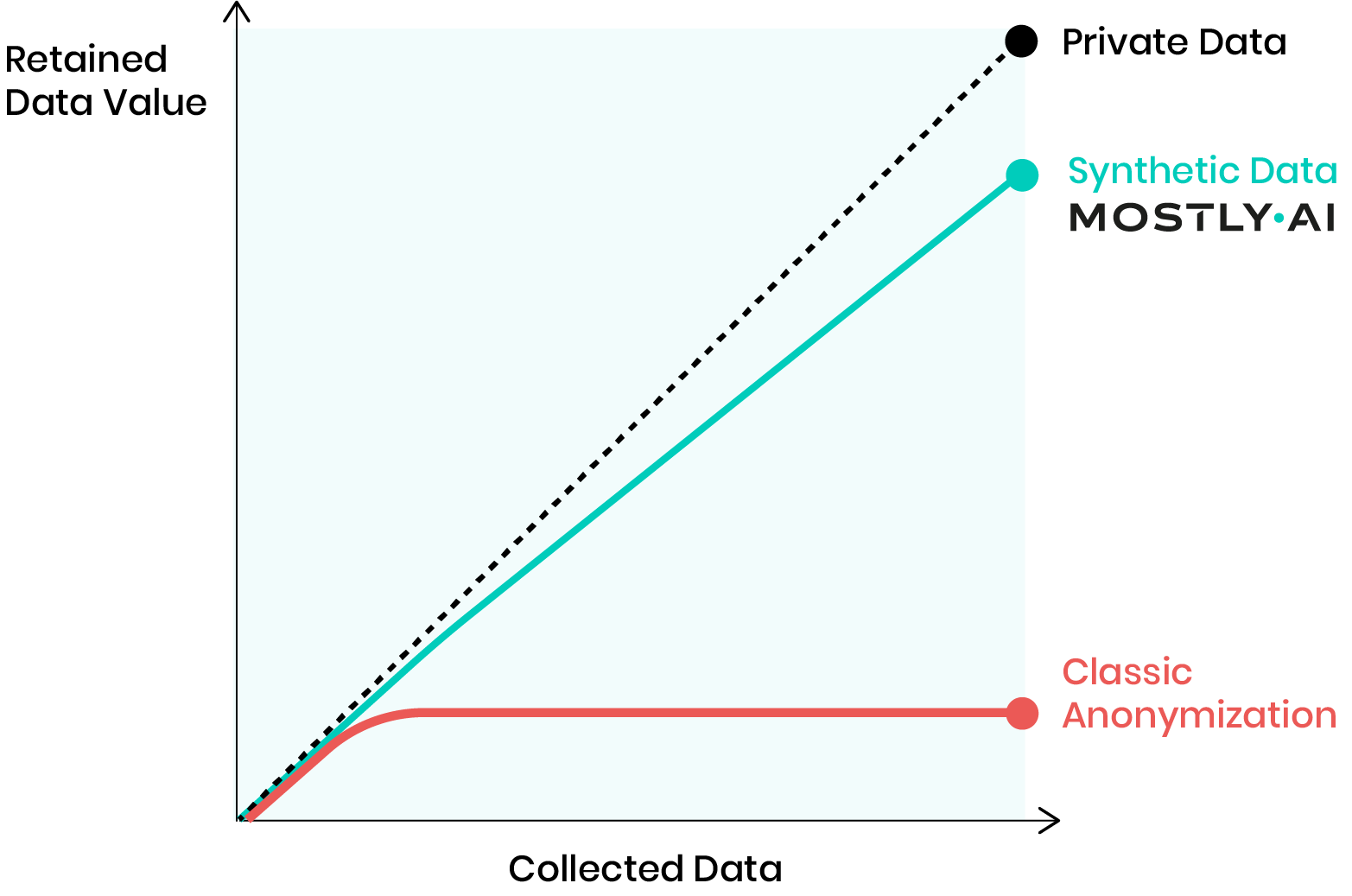
If the database isn't big enough, the AI should be able to input more data into it and make it more diverse. And if the database does contain a large number of inputs, synthetic data can make it diverse and make sure that no one was excluded or mistreated.
The good news is that generating data is less expensive. Real-life data requires a lot more work, such as collecting or measuring data, while synthetic data can rely on machine learning. Besides saving a lot of money, synthetic data also saves a lot of time. Collecting data can be a really long process.
For example, let's say we are operating with a facial recognition algorithm. If we show the algorithm more examples of white people than any other race, then the algorithm will work best with Caucasian samples. So we should make sure that enough data has been produced that all races are equally represented.
Synthetic data does have its limitations. There isn't a mechanism to verify if the data is accurate.
AI is obviously having a significant role in the insurance sector. By the end of 2021, hospitals will invest $6.6 billion in AI. But it's still essential to have human involvement to make sure the algorithmic bias doesn't have the last say. People are the ones that can focus on making algorithms work better and overcoming bias.
See also: How AI Can Vanquish Bias
Explainable AI
Because we can't entirely rely on synthetic data, a better solution may be something called "explainable AI." It is one of the most exciting topics in the world of machine learning right now.
Usually, when we have a certain algorithm doing something for us, we can't really see what's going on in the work with the data. So can we trust the process fully?
Wouldn't it be better if we understood what the model is doing? This is where explainable AI comes in. Not only do we get a prediction of what the outcome will be, but we also get an explanation of that prediction. With problems such as algorithmic bias, there is a need for transparency so we can see why we're getting a specific outcome.
Suppose a company makes a model that decides which applications warrant an in-person interview. That model is trained to make decisions based on prior experiences. If, in the past, many women got rejected for the in-person interview, the model will most likely reject women in the future just because of that information.
Explainable AI could help. If a person could check the reasons for some of these decisions, the person might spot and fix the bias.
Final words
We need to remember that humans make these algorithms and that, unfortunately, our society is still battling issues such as racism. So, we humans must put a lot of effort into making these algorithms unbiased.
The good news is that algorithms and data are easier to change than people.



